Last year I was using AI Chat and Copilot but hadn't gone all in on coding agents yet. I was seeing AI slop everywhere. But in Dec 2025 everything changed and I reevaluated my whole approach.
"When the facts change, I change my mind." -- John Maynard Keynes
The facts changed. So did I.
The paradox
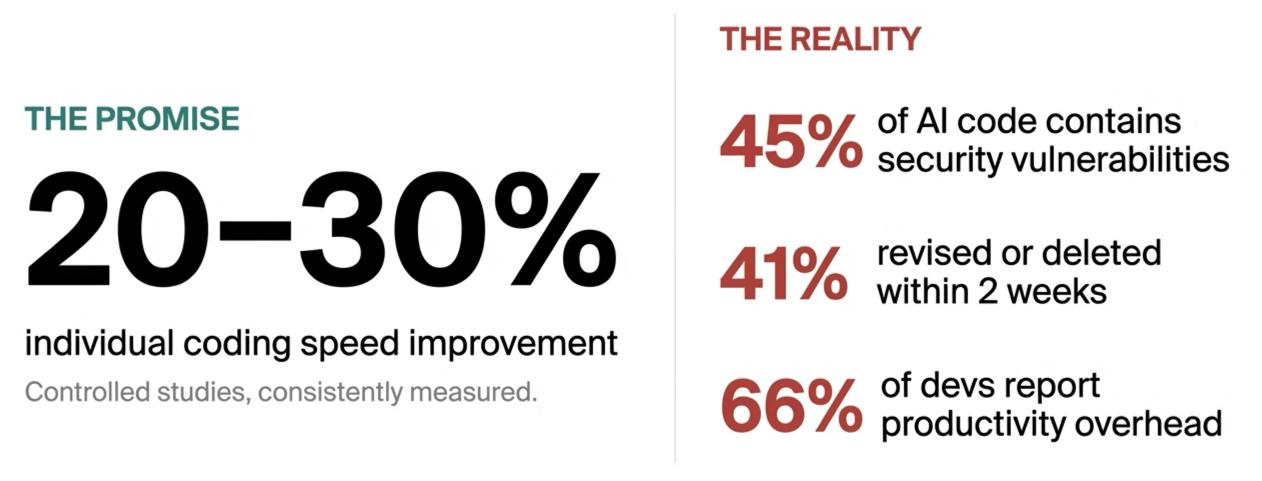
I looked for research and found the conflicting data.
Controlled studies consistently show 20–30% individual coding speed improvements [1]. But research also shows that 45% of AI-generated code contains security vulnerabilities [2], AI code has a 41% higher churn rate, revised or deleted within two weeks [3], and in the 2025 Stack Overflow Developer Survey, 66% of developers said they suffered a productivity overhead from not-quite-right AI code.
You're faster, but the output quality creates drag that can eat those gains and then some.
The question isn't whether AI coding tools are useful. They clearly are. The question is whether you end up as an AI engineer or a sloperator. You are producing more code, faster, but is most of it slop?
For greenfield projects, simple standalone apps, small, well-defined scopes, it's much easier to get good results from AI. In a few hours you can ship what would have taken days before. But for complex tasks in 10-year-old legacy codebases with intricate dependencies and undocumented conventions, that's where the slop factory kicks in.
The models are getting better, and learning the right techniques makes the difference.
The fundamental constraint
The insight that underpins everything else: LLMs are stateless. They have no memory between requests. The only thing they have to work with is the context you give them.
Context is everything. Output quality is directly bounded by context quality.
I think about context quality across four dimensions, a framing from Dex's "No Vibes Allowed" talk [5] that crystallised much of what I'd been stumbling towards. I've mixed in my own experience and pulled from other sources [6][7][8], but Dex's framework is the backbone of this post.
Correctness: is everything in the context actually accurate? One wrong assumption about how the auth system works and everything downstream is built on sand.
Completeness: is anything important missing? If the model doesn't know about a critical constraint, it can't account for it.
Size: is the context all signal with minimal noise? This one is counterintuitive, and it's the most important.
Trajectory: does the shape and flow of the conversation help the model reason well? A meandering back-and-forth produces worse results than a clean, focused prompt.
Get all four right and you get great output. Any one of them off and you get slop.
Context rot and the smart zone
As you use more tokens the model can pay attention to less and can reason less effectively
— Jeff Huber (Chroma)
At first it might seem counterintuitive that more context usually means worse output.
As you fill up the context window with more tokens, the model's ability to pay attention to all of it decreases. Its reasoning quality degrades. I've seen this called context rot [6]. Performance peaks when the context is focused and clean, then drops off.
After about 40% context window utilisation, you're in diminishing returns territory. Some call this the "dumb zone" [7].
This explains so much of the AI slop problem. People stuff context windows full, thinking more information means better results. The opposite is true.
There's a DJ analogy [8]: "if you're redlining, you ain't headlining." In audio engineering, redlining means pushing your levels past the maximum. The signal clips, distorts, sounds terrible. The pros keep headroom. They stay within the limits. That's where the clean sound is.
Same with LLMs. Stay in the smart zone. Keep headroom.

The solution: Research, Plan, Implement
If cramming context is the problem, intentional compaction is the solution. And the shape of that solution will look familiar to anyone who's been engineering for a while: research first, plan second, build third. That's not a new idea. What's new is why it matters so much more with AI. When a human developer skips the planning phase, they still carry implicit context in their head. When an AI agent skips it, it has nothing. The model only knows what's in the context window. If it's not in the context window then it will be influenced by it's training data and that's where hallucinations start to creep in.
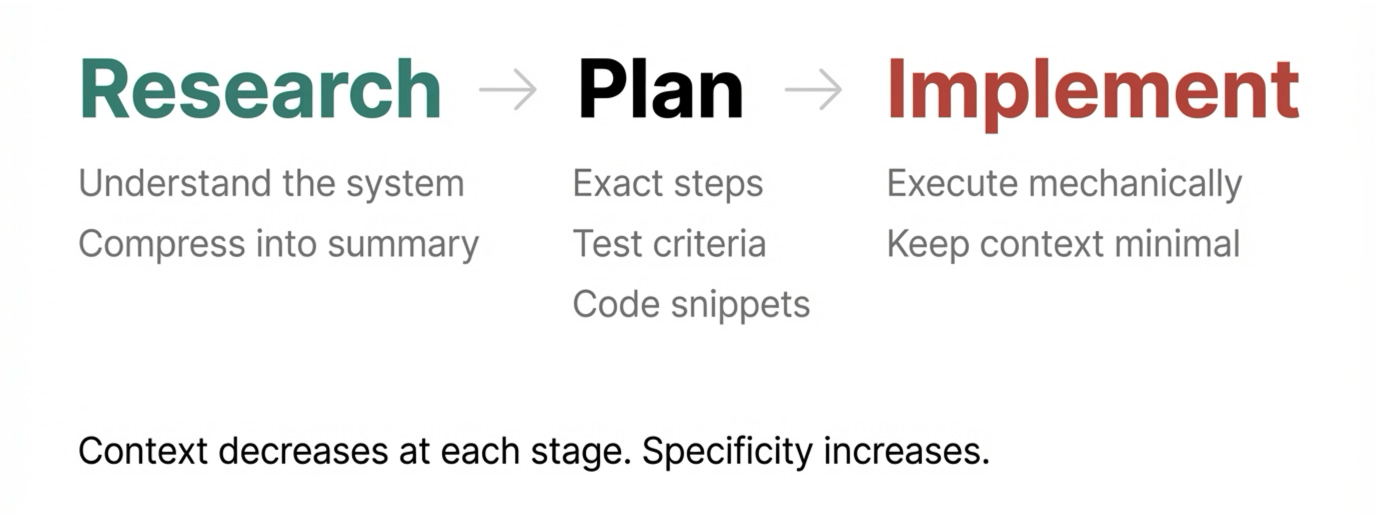
The framework I'm using has three main phases, each in a separate conversation with a fresh context window. The output of each phase is a compressed artefact that becomes the input for the next.
Phase 1: Research
Start with high context: lots of code, lots of files. Explore the codebase. Navigate the file structure, read key modules, trace data flows. Identify patterns: coding conventions, architectural decisions, existing abstractions. Map dependencies: what touches what, where the integration points are.
The output is a compressed markdown summary. Not a raw dump of files. A focused, curated document that captures what matters. AI subagents are excellent at this. You can spin them up to explore different parts of the codebase in parallel and consolidate the results.
This is the highest-leverage phase. A hallucinated assumption about how your authentication works isn't a code-level error. It's a research-level error. Everything built on top of it will be wrong.
Phase 2: Plan
Take the compressed research and produce an execution blueprint. Every step numbered, sequential, unambiguous. Include explicit test criteria: how to verify each step works. Include actual code snippets from the existing codebase to anchor the implementation to real patterns. Think through edge cases and risks.
The goal: a plan so detailed that the dumbest model in the world won't screw it up.
One bad step in the plan can produce a hundred lines of wrong code. Review plans with the same rigour you review code. Maybe more.
Phase 3: Implement
This should be the simplest phase. If research and planning are done well, implementation becomes almost mechanical.
Feed the AI only the plan and the specific files it needs to modify. Phase large tasks into chunks, each with a fresh context window. Test after each step. Build intuition for task size versus context consumption.
Don't dump the entire codebase. Don't let one conversation run forever. Don't skip testing. Don't assume more information means better output.
The pattern across all three phases: context goes down at each stage while specificity goes up.
The hierarchy of leverage
Not all errors are created equal [5].
A bad line of code is a bad line of code. You'll probably catch it in review. A bad step in a plan could produce a hundred lines of wrong code before anyone notices. A fundamental misunderstanding of how the system works, a research-level error, means your entire feature is built on a wrong assumption.
Don't just review code. Review plans. Review research. Catch errors before they multiply.
You can use the AI itself as a reviewer, but know where it's reliable. At the code level, it's excellent: syntax errors, logic bugs, missing edge cases. At the plan level, it's moderately useful. It can spot gaps and inconsistencies but still needs human judgement. At the research level, it's less reliable because it requires the kind of deep system understanding the model may not have.
Human review is non-negotiable at the research and plan level. AI review amplifies your coverage at the code level.
Don't let it guess
The default behaviour of most models is to be helpful. When they encounter ambiguity, they make a plausible-sounding decision and keep going.
That's the most dangerous failure mode.
A compiler error is obvious. A failed test is obvious. A hallucinated line of code, you'll probably catch it in review. But a confidently wrong architectural choice buries itself in your codebase and surfaces weeks later. A hallucinated assumption about how your auth system works poisons everything downstream.
The fix: force the model to ask rather than guess. In every prompt, explicitly instruct it to only use the provided context and ask for clarification when anything is unclear. Use an AGENTS.md or CLAUDE.md file to set interaction-style rules that get included automatically in every prompt. Set it once, applies everywhere.
Yes, sometimes this means the AI agent asks too many questions. I'd rather it ask "does this service use JWT or session tokens?" than confidently guess wrong and build an entire feature on a bad assumption.
An interruption is cheap. A hallucinated assumption is expensive.
Configuration as free performance
A quick note on setup: research shows 10–20% improvement in output quality from getting configuration right. That's free performance you're leaving on the table if you skip it.
Three areas matter. AGENTS.md / CLAUDE.md defines your coding conventions, project-specific rules, and interaction style. It's included in every request automatically. MCPs (Model Context Protocol servers) are powerful integrations, but they eat context, so be selective and disable what you're not using in this session. Skills are progressive disclosure: specialised knowledge provided only when needed, not loaded all at once.
Everything is a context budget decision. Every MCP, every file, every instruction consumes tokens from your smart zone budget.
For structured prompts, I use six elements: role (sets expertise level), goal (defines success criteria), context (constrains the solution), format (specifies deliverables), examples (anchors to your patterns), and constraints (makes security and performance requirements explicit). You don't always need all six, but for complex work, the more explicit you are, the less the model guesses.
Better models amplify everything
The models are getting better fast. Opus 4.5 was a genuine step change for coding. But a better model doesn't fix bad context management. It just produces more confident, more fluent slop.
These practices become more valuable as models improve because you're amplifying a stronger base capability.
Clean context plus a great model equals extraordinary results. Noisy context plus a great model equals expensive slop.
Same principle. The hard work here is in context management, not in writing more code.
Will this age?
An obvious question: context windows are getting bigger, tools are getting smarter at managing context automatically, agents can search and index codebases on their own. Will any of this matter in a year?
Some of the specifics won't. The 40% utilisation threshold will shift. The manual three-phase workflow will probably get automated. The tooling around AGENTS.md and MCPs will evolve or be replaced entirely.
But I think the underlying principles hold. "Be intentional about what the model knows" is a constraint of attention, not just of window size. A million-token context window doesn't help if the model is paying equal attention to everything and nothing is prioritised. "Review at the highest leverage point" is just good engineering. "Don't let it guess" is about the nature of language models, not the current generation of them.
The tools will change. The thinking won't. Or at least, that's my bet.
The difference
The gap between drowning in AI slop and shipping quality code comes down to four things:
Intentional context management. Understand the smart zone. Keep context clean, compressed, and focused. Less is more.
Research, Plan, Implement. Separate your phases. Compress between each one. Fresh context windows. Specificity up, noise down.
Human review at the highest-leverage points. Don't just review code. Review plans and research. Catch errors before they multiply.
Never let it guess. Force the model to ask questions. An interruption is cheap. A wrong assumption is expensive.
These aren't complicated ideas. They're intentional ones. And that intentionality is what separates AI engineers from sloperators.
If you're using AI coding tools and have found practices that work for you, or if you think I've got it wrong, I'd love to hear about it. Drop me a line.
References
[2] AI-Generated Code Security Risks
[3] AI Assistant Code Quality 2025 Research
[4] A New Worst Coder Has Entered the Chat
[5] No Vibes Allowed: Solving Hard Problems in Complex Codebases
[6] Context Rot: How Increasing Input Tokens Impacts LLM Performance