These days I spend much more of my development time reviewing code than writing it myself. I've also found myself thinking more deeply about what to build, and how to specify it, before anything gets generated. I wrote recently about thinking in plans, not code and how the leverage has shifted upstream to research and planning. This post is about the other side: what happens downstream, when the code arrives and you have to decide whether it's right.
The Human Constant
There's a chapter in Making Software (Oram & Wilson, O'Reilly) that summarises two studies on code review effectiveness.
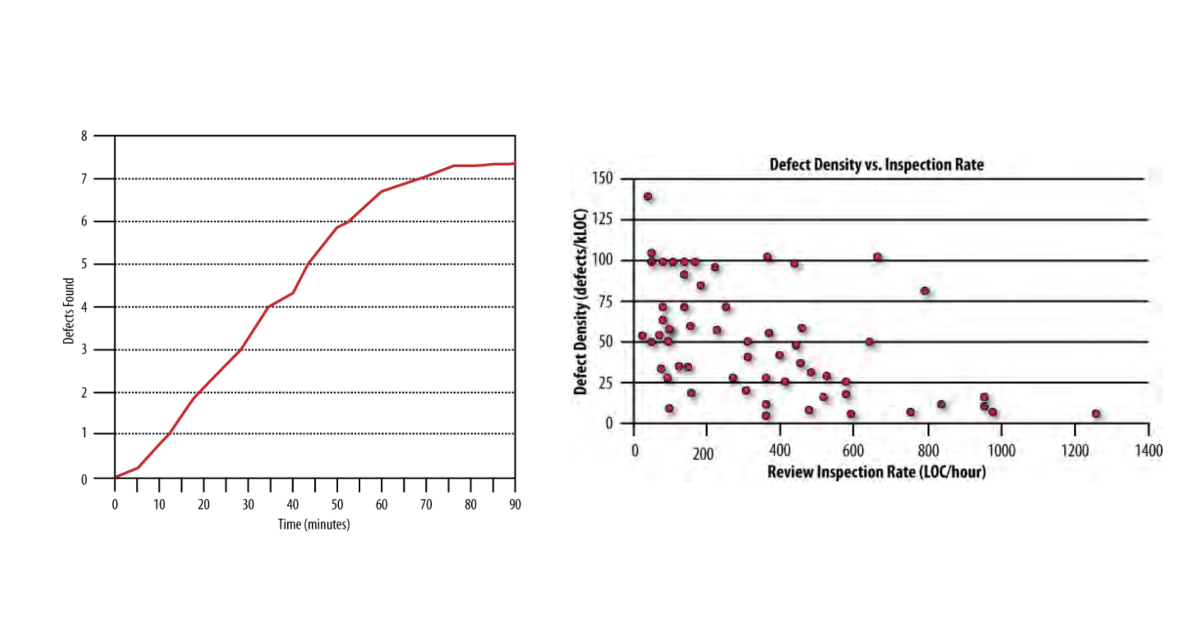
The first (Dunsmore 2000) mapped defect detection over time. Early in a review, the relationship is linear: roughly one defect found every ten minutes. But around the 60-minute mark, there's a sharp drop-off. Another ten minutes no longer reliably turns up another defect. The brain hits a wall.
The second (Cohen 2006) looked at around 2,500 reviews and measured the effect of review speed. Below about 400 lines of code per hour, defect density spreads naturally across reviews. Some code is simple with few defects, some is complex with many. That spread is normal. Above 400-500 LOC/hour, high defect density reviews virtually disappear. Not because the defects aren't there. Because the reviewer is moving too fast to find them.
The conclusion: at most one hour, at most 400 lines. Review more than that in a single sitting and you're not going to be effective.
These are cognitive limits. They haven't changed. What's changed is the volume of code arriving at your desk. An AI coding assistant can produce in minutes what used to take a developer a day. The production side has scaled. The review side is still bounded by the same brain it always was.
The Coherence Problem
AI-generated code tends to look fine in isolation. Each function is reasonable. Each module makes sense on its own. The issues that are easy to miss are not bad code. It's code that doesn't make sense when you look at the bigger picture.
Three modules that solve overlapping problems in slightly different ways. Abstractions that don't compose because they were never designed together. Naming conventions that drift across files. Local coherence, but not global coherence.
In a traditional team, this kind of drift happens too, but it happens slowly. Over weeks, conversations and reviews naturally surface the divergence. Someone says "wait, didn't we already solve this?" and the team realigns. With AI, the same mess can accumulate in an afternoon. The code all looks clean, so the signals that would normally trigger a course correction don't fire.
I had a telling example recently. I'd specified RustFS in my requirements for integration testing some S3 code. By the time the AI-generated plan came back, that had quietly become Minio, the more widely known option. The substitution looked perfectly reasonable at a glance. I missed it. One line in a plan that would have been a trivial correction became an extra round of implementation to revert and swap out the dependency.
That's the leverage problem in miniature. Catching it in the plan costs you a one-line edit. Catching it in the code costs you a cycle of rework.
Right-Size the Unit of Work
One response to the review bottleneck is to control what you're generating in the first place. I've found a rough guideline: size tasks and planning phases so they fit within about 40% of the AI's context window. That's around where context rot starts to bite, the gradual degradation in output quality as the context fills up.
It's not a hard rule. But it serves two purposes. It keeps the AI's output consistent and reliable. And it keeps each chunk of output within a budget that a human can actually review properly, given the cognitive limits above.
Approval checkpoints need the same kind of sizing. Too many interrupts and you overwhelm the human reviewer with constant context-switching. Too few and drift goes unchecked until it's expensive to fix.
There's no formula for this yet. Both sides, human and AI, are developing intuition for what works. It builds through practice, is context-dependent, and not something you can read off a chart.
Review Plans, Not Just Code
Human attention is most valuable at the levels where AI is weakest: specifications, requirements, and architectural coherence. The review question shifts from "is this code correct?" to "is this spec complete?" and "does this still hang together?"
Going back to that RustFS example, if I had reviewed the plan more carefully, catching the substitution would have been a one-line correction. Instead, I caught it after implementation, and it cost a rework cycle. The same principle applies at every scale: the earlier you apply human judgment, the cheaper the correction.
Senior developers' experience and context matter most here. The ability to hold the bigger picture, to spot when a plan is subtly drifting from what the system needs, to ask "have we already solved this differently elsewhere?" That's the work.
Make Verification Deterministic
Every check you can make deterministic is a check you take off the human reviewer's plate. Strongly typed languages catch entire categories of error at compile time. Linters enforce consistency across files without anyone reading them. Automated tests verify behaviour. Security scanners flag known patterns. Contract tests confirm that modules still talk to each other correctly.
None of this is new. But in an AI-augmented workflow these tools go from helpful to essential. They're what make the review budget viable, because they remove whole classes of concern from the pile of things a human has to think about. The more you push into deterministic verification, the smaller the surface area of judgment-dependent review becomes.
Never send an LLM (or a human) to do a linter's job.
Triage Before You Review
When you do sit down to review, start with a fast architectural pass. Does the overall shape make sense? Do the modules fit together? Are the boundaries in the right places? Only then focus your attention on the parts that carry the most risk: security boundaries, data validation, error handling, concurrency.
AI can help here too as a first-pass. AI can triage to direct your attention rather than replace your judgment. Let it flag the areas that look unusual or complex, then spend your limited review time on those.
Make the AI Account for Its Decisions
One practice I've found useful: after implementation, ask the AI to report where and why it deviated from the plan. It won't catch everything (it can be blind to its own substitutions), and it can tend to go into detail on where it followed the plan, not deviated. If you can successfully prompt for this, it shifts the review from reading every line looking for surprises to taking a more targeted approach as to where you focus your attention more.
Again, back to that RustFS-to-Minio example. This should not be something you have to spot by chance but rather something that gets surfaced for you. The AI might tell you "I used Minio instead of RustFS because the test container support is more mature." Now you have a decision to make rather than a detail to catch. That's a better use of your attention.
What Changes
This requires a genuine shift in how senior developers think about their work. The high-leverage activity isn't reading code line by line any more. It's writing specs tight enough that generation is constrained, reviewing plans before they become implementations, and maintaining the coherent bigger picture that no individual AI context window can hold.
That's harder to measure than lines reviewed. It's harder to put in a standup update. But it's where the bottleneck actually is, and it's where experienced developers can make the work better, or, by not doing it, let it quietly degrade.
If any of this resonates, or if you've found approaches that work differently, drop me a line.