I've been building software for over 25 years and I've been through many changes to how we work in that time. There was Git, CI/CD, cloud, containers to name a few. This is the biggest change in the shortest space of time. In December 2025, Claude Code and Opus 4.5 crossed a threshold.
Since then I've been focusing all my energy on this: working with AI coding agents in production every day, experimenting, noticing what works, feeding that back into my process. The approaches out there range from spec-driven development to fully autonomous vibe coding. What follows is where I've landed, built from daily use on real projects. It keeps changing.
This isn't science. It's field reporting from a practitioner going deep on this every day, testing what works under real conditions. Some of what I've found aligns with what others in the field are discovering independently. Some, I think, goes further.
The core principle
One observation underpins everything: LLMs are stateless. They have no memory between requests. Output quality is bounded by context quality.
Better models don't fix bad context. They produce more confident, more fluent slop. In the 2025 Stack Overflow Developer Survey, trust in AI accuracy dropped from 40% to 29% year-over-year, even as 84% of developers kept using the tools. People keep using them because they're genuinely useful. The output quality is the problem to solve.
The difference between shipping quality and drowning in rework comes down to how deliberately you manage what goes into the context window and how rigorously you verify what comes out.
A toolkit, not a pipeline
My process is not a linear pipeline. It's a toolkit of distinct steps that I assemble into a custom flow for each piece of work. The shape depends on the outcome I'm after. Each step runs in a fresh context window, with the output compressed into a focused artefact for the next. Context goes down at each stage while specificity goes up.
I've tried to formalise this into a deterministic workflow, a controlled set of steps I can repeat. I might be converging on something: a custom orchestration and review tool built to maximise human leverage at the points where it matters most. But that's early days. For now, the value is in keeping it flexible, experimenting with how the pieces fit together, and adjusting as I learn what actually holds up under daily use.
The available steps and a typical flow:
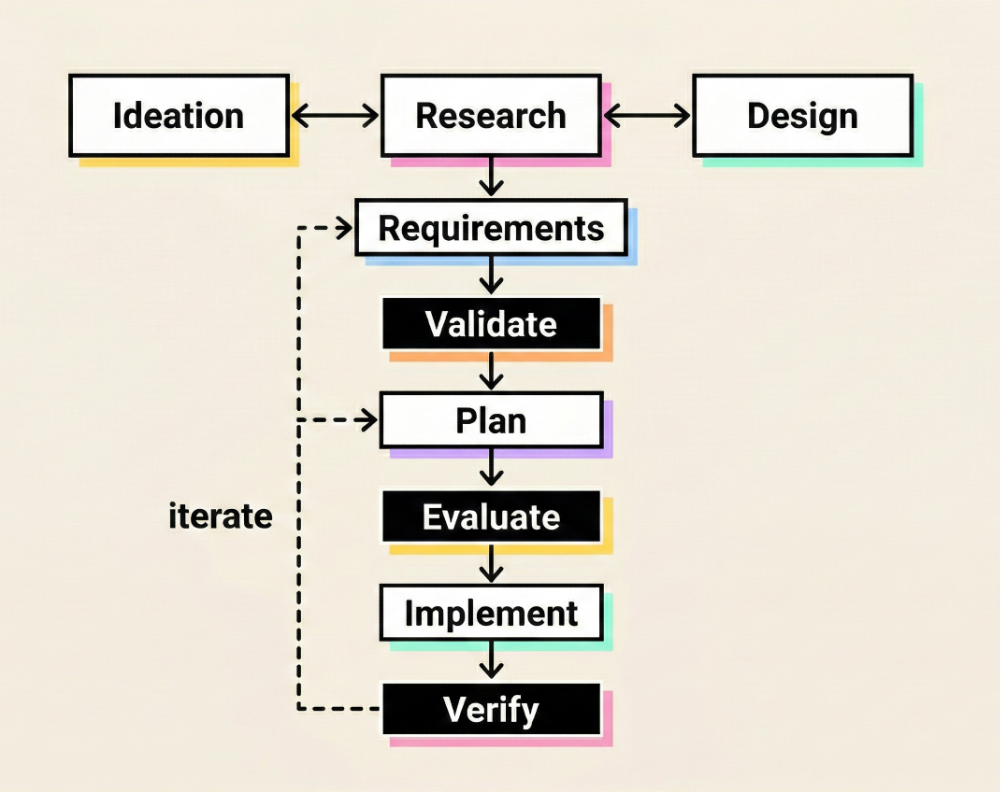
Ideation, design, and research feed each other iteratively, sometimes in parallel. Requirements crystallise from that exploration. Then the three review stages, validate, evaluate, verify, each check different things at different points.
These steps aren't always all present. For a small bug fix, several collapse into one session. For a substantial feature, each is a distinct conversation with its own context window. I assemble the flow to fit the work, not the other way around.
Research
This is the highest-leverage phase. The goal is to map the problem space: relevant files, functions, data flows, constraints, prior decisions. Not to write code.
Sub-agents do the noisy work in isolated context windows: file exploration, code search, dependency tracing. Their compressed summaries come back to the main context clean, without the search noise that would pollute it. This is encapsulation, applied to attention rather than code.
The pattern is gather, then glean. Cast a wide net first (maximise recall), then cull to the minimal set that matters (maximise precision). The most dangerous information isn't the obviously irrelevant stuff. It's information that looks relevant but isn't. A hallucinated assumption about how the auth system works isn't a code-level error. It's a research-level error. Everything built on top of it will be wrong.
Plan
An execution blueprint. Every step numbered, sequential, unambiguous. Include test criteria and code snippets where they remove ambiguity. The target: a plan so specific that implementation becomes almost mechanical.
This is where small mistakes get expensive fast. A bad step in a plan produces hundreds of wrong lines. I've had a single missed detail in a plan generate a cascade of not-quite-right code across multiple files, all internally consistent, all confidently wrong. The earlier you apply human judgement, the cheaper the correction.
Implement
Should be the simplest phase. Feed the plan and only the specific files needed. For larger tasks, break implementation into chunks, each in a fresh context window, to stay below roughly 40% context window utilisation, where I've found output quality starts to drop off noticeably.
In practice, this means I can run plan steps through an implementation loop: feed a step, execute, commit, fresh context, next step. This is close to what people are calling a Ralph loop (Geoffrey Huntley's pattern of running an agent repeatedly with git as the memory layer), but structured around a plan rather than re-running the same prompt until it converges.
What I add on top is a deviation log. During implementation, any point where the AI diverges from the plan gets flagged with a reason. I review and annotate these. This turns code review from reading every line to targeted investigation of the places where plan and reality didn't match.
Three review points, not one
Most workflows put review at the end. I apply human judgement at three distinct points, each in a fresh context to avoid bias from the previous phase.
Validate (after requirements): Are we solving the right problem? Are the requirements correct, complete, and feasible? This catches scope errors before any planning or code exists.
Evaluate (after plan): Is the approach sound? Is the work broken into chunks that fit within the AI's context sweet spot? Does each chunk specify the context it needs? A plan that looks right but is poorly chunked for execution will produce inconsistent output.
Verify (after implementation): Does the output match the plan and requirements? This is where all forms of review converge:
- Static analysis first. Types, linters, automated tests, security scanners. I write Rust, and the compiler's error messages are detailed enough that the agent can interpret and fix them directly. Never send an LLM or a human to do a linter's job.
- Architecture second. Check structural decisions: dependencies, patterns, interfaces, how the new code fits the existing system.
- AI-specific failure modes last. AI-generated code tends to have local coherence (each module works in isolation) but poor global coherence (three modules solving overlapping problems differently, abstractions that don't compose, naming drift). Security is where the failures get dangerous. AI won't add CSRF protection, rate limiting, or input validation unless specifically prompted. It builds what you ask for, not what you need.
The research is clear: 45% of AI-generated code contains security vulnerabilities. AI pull requests average 1.7x more issues than human PRs. If you only verify at the end, you're trying to catch all of that in code review. Validate and evaluate earlier, and many of those issues never get generated in the first place.
Context management
I think about context quality across four dimensions, a framing from Dex Horthy's "No Vibes Allowed" talk that I've found genuinely useful:
- Correctness: Is everything in context accurate?
- Completeness: Is anything important missing?
- Size: All signal, minimal noise. Keep the model in its smart zone.
- Trajectory: Does the conversation flow help the model reason well?
The roughly 40% guideline
The 40% figure comes from Dex Horthy. My experience confirms it: best performance is below 50% utilisation, and quality drops noticeably beyond that. Chroma's context rot research confirms the underlying principle: model performance decreases as input length grows, even on simple tasks. More context usually means worse output, not better. The practical rule: if you're approaching the limit, start a fresh context or delegate to a sub-agent.
Summarise and delegate
Two strategies for keeping context under control.
Summarise is reactive. Compact accumulated context between phases. The output of research becomes a compressed summary for planning. The plan becomes a compressed spec for implementation. Each transition is an intentional reduction.
Delegate is preventive. Hand work to sub-agents with isolated context windows so token sprawl never reaches the main agent. Sub-agents explore different parts of a codebase in parallel; only their compressed summaries come back. The sprawl never enters the main context at all.
Anthropic's guidance on context engineering formalises these as four strategies: write, select, compress, and isolate. My summarise maps to their compress; my delegate maps to their isolate. The underlying principle is the same: every token in the context window competes for the model's attention, so be deliberate about what goes in.
Configuration: deterministic vs instructed
A sharp distinction runs through my entire setup. Anything that can be checked mechanically is enforced via hooks or automated verification steps, not by instructing the LLM. Linting, type checking, test runs, security scans, formatting. These run automatically because the toolchain demands it. The LLM doesn't need instructions to follow rules that are enforced by the compiler.
Factory.ai put this well: "Agents write the code; linters write the law." When you encode your architecture and standards directly into the code generation loop, the AI generates code, gets automatic feedback, and iterates until clean. Lint passing becomes a proxy for "conforms to architecture and best practices."
Only non-deterministic behaviour controls go in instruction files like CLAUDE.md. Coding conventions that linters
don't capture, architectural preferences, domain-specific patterns, interaction style, when to ask for clarification vs
proceed.
...use the AskUserQuestion tool...
The single most important instruction I give the agent: ask me rather than assume. If the context isn't enough, if there's a trade-off to resolve, if research turns up conflicting options, stop and ask. Most AI failures I've seen trace back to the model filling gaps with confident guesses instead of flagging uncertainty. Prompting for this aggressively has done more for my output quality than any other single instruction.
Skills extend these non-deterministic instructions with progressive disclosure. Modular prompt definitions loaded only when relevant. They keep the base context lean and bring in specialised instructions on demand: commit conventions, review criteria, planning templates, domain-specific patterns.
Hooks are how the deterministic side gets enforced. Claude Code fires hooks on events like file saves and tool calls. I use them to enforce rules, so the agent gets immediate feedback without being told to check. The agent fixes issues in the same loop. No instruction needed, no judgement required.
MCP servers are powerful but hungry. Every tool description loaded into context competes for the same attention budget as the actual task. Be selective. Only connect what you'll actually use for the current work.
The review bottleneck
AI has scaled code production. Human review capacity hasn't changed. The research summarised in Making Software ( Oram & Wilson, O'Reilly) is consistent: roughly 400 lines per hour for effective review, with a hard wall at about 60 minutes of sustained attention. Beyond that, defect detection falls off a cliff.
AI-generated code has a 41% higher churn rate than human-written code. And an eight-month study of 200 employees found 83% said AI increased their workload through scope expansion and dissolved work boundaries.
This is the central constraint. My strategies for working within it:
Right-size the unit of work. Size tasks to stay within both the AI's context sweet spot and the human review budget. These constraints push in the same direction, which is convenient.
Validate and evaluate, not just verify. Human attention is most valuable at the requirements and plan level, where AI is weakest and the cost of errors is highest.
Make verification deterministic. Strongly typed languages, linters, automated tests, contract tests, security scanners. These go from helpful to essential in AI-augmented workflows. They handle the mechanical correctness that humans shouldn't spend review time on.
Triage before deep review. Fast architectural pass first, then focus on risk areas: security, data validation, error handling, concurrency.
Make the AI account for deviations. The deviation log from implementation turns review into targeted investigation rather than line-by-line reading.
The no-review shortcut
There's a growing school of thought that if you checked the plan and the code seems to work, you can skip review and ship. I understand the appeal. You can't inspect all the code the way we did before. The volume has changed.
But AI code goes wrong in different ways than human code did. The failure modes I described above, poor global coherence, missing security controls, naming drift, these aren't the kind of bugs that surface immediately in a demo. They accumulate. Skipping review because the code appears to work ignores the problems that don't surface until production: inconsistency, missing security controls, accumulated debt.
Then there's compliance. Both SOC 2 and ISO 27001 have controls that require change management and peer review. The purpose of code review isn't just catching bugs. It's establishing an auditable trail of authorisation. Could you substitute automated testing, static analysis, and post-deploy monitoring as compensating controls? Maybe, in some configurations. But you'd need to document that thoroughly, get buy-in from your auditor, and demonstrate it's equally effective. Most organisations would find it far easier to just do code reviews than justify the alternative to an auditor.
The answer isn't to skip review. It's to scale it, focus it, and make it sustainable. Which is what everything above is trying to do.
Cognitive debt and operational knowledge
There's a concept gaining traction called cognitive debt: the gap between the code your team ships and the code your team actually understands. Margaret Storey framed it well, and Simon Willison amplified it. The research suggests AI generates code 5-7x faster than humans can comprehend it.
I think the problem goes deeper than code comprehension. AI can build fast. You cannot compress the learning that comes from running a system in production with real users over time.
An LLM will build what you ask for but won't volunteer what you haven't thought to ask for. And the things you haven't thought to ask about are exactly what matters most in production. Payment timeouts. Reservation expiry race conditions. Idempotency edge cases. I've encountered all of these through operating my own systems, not through planning or design.
The gap between what you can build and what you can operate is where trust breaks. AI-augmented development widens this gap by accelerating the build side without touching the operational learning side.
The practical response: build deliberately. Simple first. Real usage from day one. Complexity only as the system proves itself. AI assists everywhere, but the human decides everywhere.
Where AI adds genuine value
Not everywhere.
Where it works: Unstructured-to-structured transformation (parsing inconsistent data formats that would previously require brittle regex or hand-coding). Natural language interfaces, always with a human in the loop. Code generation with disciplined context management. Parallel research and exploration via sub-agents.
Where it doesn't: Replacing deterministic workflows. There is no good reason to replace a reliable cron job, webhook, or message queue with a non-deterministic alternative. Unsupervised autonomous operation: an AI agent with API keys and shell access on a timer is a security incident waiting to happen. And anywhere robustness matters more than novelty. If the existing solution works reliably, the burden of proof is on the AI replacement.
How this compares to the field
This process aligns with several emerging practices. The research-plan-implement workflow mirrors what Dex Horthy, Anthropic, and Simon Willison independently advocate. Context engineering as the central discipline matches Jeff Huber's framing. Plan-first, spec-driven development has become the consensus position, replacing the early "vibe coding" enthusiasm.
Where I think this approach diverges:
Deterministic enforcement over LLM instructions. Most guides put everything in CLAUDE.md or similar files. I
reserve instruction files for genuinely non-deterministic guidance and enforce everything else through hooks and
tooling. If a machine can check it, a machine should enforce it.
Operational knowledge as the constraint, not code generation speed. The industry conversation focuses on how fast you can ship. I think the gap between build speed and operational understanding is the primary risk. Cognitive debt at the code level is real, but the knowledge that only comes from production is the harder problem.
Collaboration over autonomy. The mainstream is moving towards more agent autonomy. I'm betting that the best outcomes come from effective collaboration between AI and experienced, product-focused engineers. The human brings domain knowledge, system-wide judgement, and operational experience. The AI brings speed, parallel exploration, and tireless execution. Neither alone matches what they produce together. That's what AI-augmented development means.
The METR study (mid-2025) found experienced developers were 19% slower with AI on their own large codebases. This doesn't match my experience, and I attribute the difference to two things: context management discipline (most developers in the study used AI without structured workflows), and the step change in model quality and tooling that arrived in December 2025.
The hard part was never typing
Marty Cagan describes four product risks: value (will people use it?), usability (can they figure it out?), feasibility (can we build it?), and business viability (does it work for the business?). AI has reduced feasibility risk significantly. It has not reduced the others. If anything, by making it cheaper to build, it shifts attention back to value risk: are we building the right thing?
The process in a sentence: assemble the right steps for the work, fresh context per step, compress between transitions, enforce deterministically what you can, instruct the AI only on what requires judgement, and validate and evaluate before you verify.
This keeps evolving. I'll be wrong about parts of it in six months. But the underlying bet, that disciplined collaboration between human judgement and AI capability beats either alone, is the one I'm most confident in.
If you're working through this yourself, I'd genuinely love to hear what's working for you. Drop me a line.
Sources
- No Vibes Allowed: Solving Hard Problems in Complex Codebases (Dex Horthy, HumanLayer)
- Advanced Context Engineering for Coding Agents ( HumanLayer)
- Context Rot: How Increasing Input Tokens Impacts LLM Performance (Chroma Research)
- Effective Context Engineering for AI Agents ( Anthropic)
- Using Linters to Direct Agents (Factory.ai)
- AI-Generated Code Security Risks (Veracode, 2025)
- AI Assistant Code Quality 2025 Research (GitClear)
- State of AI vs Human Code Generation ( CodeRabbit, 2025)
- 2025 Developer Survey (Stack Overflow)
- AI Doesn't Reduce Work, It Intensifies It (HBR, 2026)
- Cognitive Debt (Margaret Storey)
- Impact of AI on Experienced Developer Productivity ( METR, 2025)
- The Four Big Risks (Marty Cagan, SVPG)
- The Ralph Loop (Geoffrey Huntley)
- Making Software (Oram & Wilson, O'Reilly)