A couple of weeks ago I wrote Code I'll Never Read, arguing that humans might not be the right reviewers of agent code. That our instincts about "good code" could be misleading us. I still think that's partly true.
But code review does more than judge aesthetics. Some of what it catches still matters. I'm trying to work out where the line is.
I'm still reading code. Software development is still a team sport, and so I review it carefully before passing it on to my team. But on side projects and experiments I'm deliberately trying different approaches, pushing the boundaries of how much I can let go and finding where it breaks down. This post is where that exploration has taken me so far.
Dex's reversal
Dex Horthy is someone I've learned a lot from. He pioneered the Research, Plan, Implement approach. Stopped reading code line-by-line, reviewed specs instead. It made sense to me. I adopted parts of it, extended it with deviation logs and targeted review. Maybe over the top, maybe not token-efficient, but it's consistently produced good work.

Then recently, in a talk, he said: "I was wrong... please read the code."
And I can relate because I haven't been able to completely give up reading the code. I'm focusing on the specs and verification. However, there's a problem with the process when you refine the specs long enough and make several review passes, you end up with implementation plans that are as complex as the code they produce. Without the determinism of code.
It was supposed to look like this:
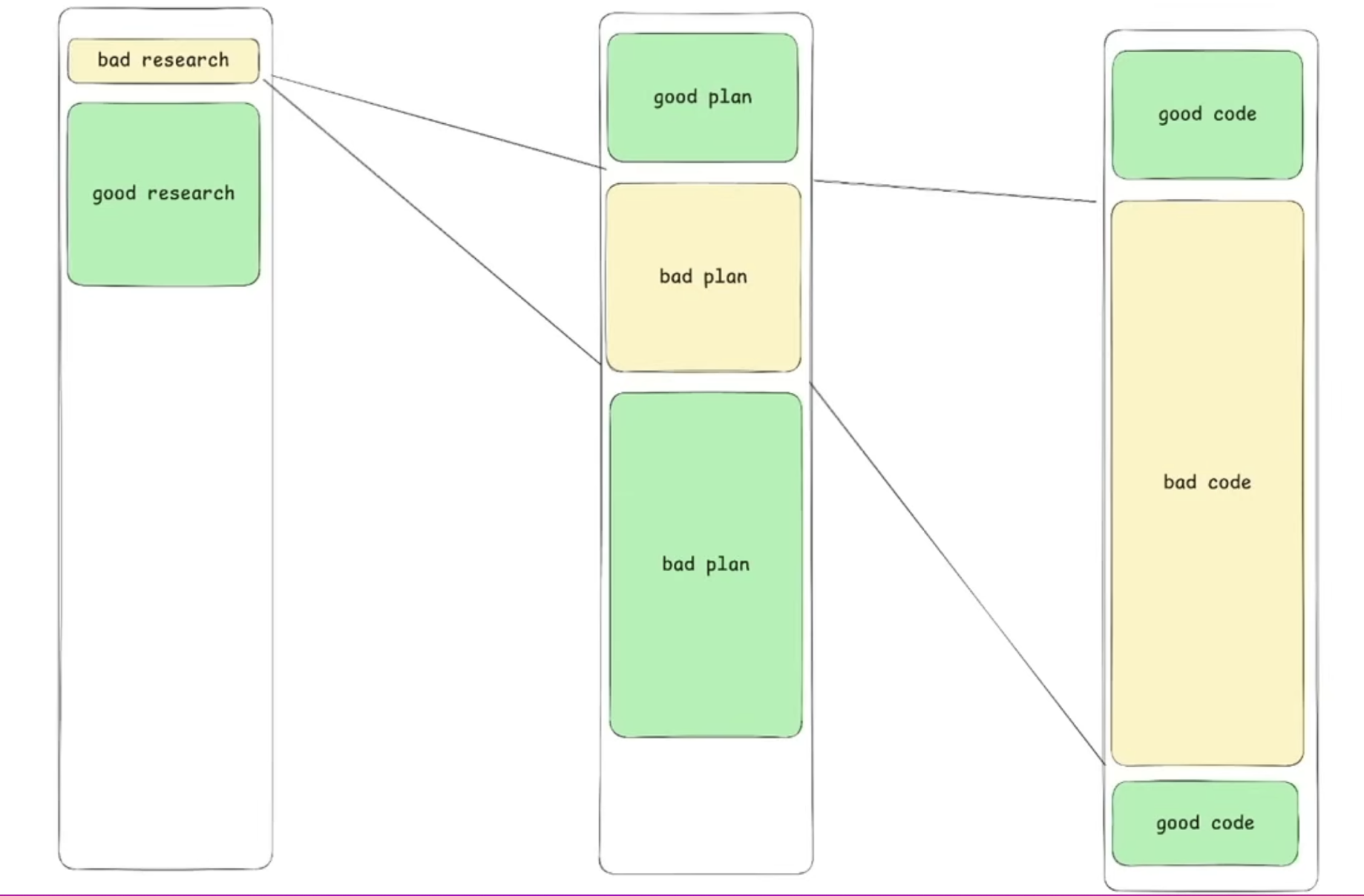
In reality, a 500-line plan would result in the same amount of code. So you are not saving anything in review time, and you get non-determinism in the output.
The leverage is gone.
The plan problem
I had a project recently where I wrote a detailed spec. The agent followed it, mostly. But the implementation diverged in ways I didn't catch until I tested the running system. The spec said one thing, the code did something subtly different, and the spec was too long for me to cross-reference efficiently.
That's the trap. Plans can get as heavy as the code itself. A spec that's as long as the implementation is just swapping one unreadable artefact for another.
And plans aren't guaranteed to be followed anyway. The agent treats your spec as context, not as a contract. It will deviate when it hits something unexpected, and it won't always tell you.
It's about leverage
The real question isn't which artefact to read. It's where you get leverage.
Agents write code fast. Humans can't keep up. You need processes that are asymmetric, where the human effort is small relative to the value of the check.
A type signature is cheap to verify and expensive to satisfy. A property test rules out infinite bad implementations in one line. An integration test catches emergent bugs that no amount of reading catches. These are the asymmetric wins.
A prose spec that's as long as the code? That's symmetric. You're still reading a big document trying to spot subtle problems. That's exactly what I said code review was bad at in the last post.
What's actually working
Here's what I've found effective across the projects where I've been experimenting.
Strong input, not long input. Clear specs with explicit constraints. Enough that the agent doesn't guess, but not a novel. The goal is to make priorities unambiguous, not to pre-write the implementation in English.
Deterministic checks on the output. Type systems, compile-time guarantees, integration tests against real state. Push as much verification as you can into things that run automatically.
Deviation logs. The agent flags where it diverged from the plan. I review the flags more than the rest of the code. This is where I focus my attention, because it's where the spec and the reality came apart.
Here's an example of a deviation log from one of my side projects:

You can see here that the plan said to use sqlx:query! that checks SQL at compile time. But because of an error the
implementation was switched to use sqlx:query which moves the check to run time. The correct thing to do would have
been run the migration and keep the compile time check.
Manual testing. Poking the running system. This catches the gaps between spec and reality that neither the plan nor the automated checks cover. It's slow, but for anything user-facing, it's still where I find the most surprising bugs.
Runtime invariants. I specify what must always be true and prompt the agent to insert assertions where it makes sense. Exercise the system in a pre-prod environment, and those assertions catch violations that static checks miss. Cheap to specify, hard to violate silently.
Observability after the fact. Instrumentation that catches what testing missed, once the code is running for real. Not every problem surfaces in a test environment.
The granularity question
If you write too much spec then you're writing the code yourself in natural language. Too little and you're vibing, and you might get lucky or you might get slop.
What works is specifying the constraints and invariants, not the implementation. Tell the agent what must be true, not how to make it true.
Then verify cheaply, using deterministic checks where possible.
I think this is where the craft is heading. Not the aesthetics of the code. Not even the quality of the plan. It's knowing what to specify and what to verify, and keeping yourself out of the bottleneck for everything else.
The global coherence problem
There's a piece of this that doesn't fit neatly into the leverage framing, and I don't have a clean answer for it yet.
An experienced developer carries a mental model of the whole system. Where the seams are, which modules talk to each other, where complexity concentrates. That overview is what keeps the system coherent as it grows. It's what stops local changes from drifting the architecture into a mess.
We're seeing this play out now. People who've vibed for months are hitting a wall. The system works, but they can't change it. Every fix breaks something else. They've lost the shape of the thing.
A well-architected system resists this. Clear boundaries, explicit contracts between modules, separation of concerns. These aren't just human aesthetics. They're what makes a codebase survivable over time.
Can you maintain that overview without reading every line? Maybe. Architectural linting, complexity budgets, integration tests that break when modules make incompatible assumptions. These are deterministic checks on structural health.
But I'm not sure they're enough on their own. Reading code strategically, not for bugs, not for style, but enough to hold the shape of the system in your head, might still be necessary. This is the part I'm still working out.
Where this leaves me
I'm not trying to be the bottleneck. But I'm not trying to lose control either. I don't want to be in a position where I can't maintain, understand, or change the things I've built. I've seen enough people hit that wall already to take it seriously.
The answer isn't reading every line. It isn't writing a plan for every line either. It's finding the checks that give you confidence cheaply and making sure they're in place before the agent runs.
If verification costs as much as execution, you've lost the leverage that agents are supposed to give you. That's the test I keep coming back to.
I'm trying different approaches across different projects, some with heavy specs, some with minimal specs and strong verification, and some where I'm deliberately hands-off to see where it falls apart. I'll report back with what I find.