Last week I read AI still doesn't work very well, businesses are faking it, and a reckoning is coming in The Register. The picture it paints is bleak: enterprise AI is mostly failing, the metrics are gamed, and the bill is coming due. I've been trying to reconcile that with my own experience, because my experience has been the opposite. AI coding agents have been a massive performance gain for me. They've made me a better developer.
In December 2025, Claude Code and Opus 4.5 crossed a threshold. The models got good enough that agents actually worked well. I started experimenting in December, and by January I'd gone deep. That's when I realised my old way of working was dead. I had to mourn my craft of 25 years while adapting.
It hasn't been smooth. I've had failures. Outputs I threw away, approaches that turned into dead ends, entire days where the AI confidently produced something that looked right and wasn't. The difference is that I've learned to treat those failures as signal. I feed them back into how I work. And that's made all the difference.
The Register article isn't wrong. The numbers are bad. But my experience says something different is possible. I've been trying to make sense of that gap.
Two ideas. The first is a way to map the problem space: a simple quadrant that clarifies what kind of problem you're actually trying to solve with AI. The second is the outer loop: the feedback practice where you keep improving how you work with AI over time, not just what the AI outputs.
The numbers, if you want them
The scale of failure is well-documented. MIT's GenAI Divide report found 95% of enterprise AI pilots delivered no measurable P&L impact. A broader analysis across 2,400+ initiatives put the figure at over 80% of an estimated $684 billion in 2025 AI investment failing to deliver intended value. 42% of companies scrapped most of their AI initiatives in 2025, up from 17% the year before.
And yet workers at 90% of companies surveyed report using personal AI tools daily, often outperforming the corporate tools their employers are spending millions on.
The quadrant: mapping the problem space
When I hear about people getting mixed results with AI, the first thing I wonder is: what kind of problem were they trying to solve? Because not all problems are the same, and I think a lot of failure comes from not being clear about this upfront.
Two dimensions matter:
Data: structured vs. unstructured. Is the input clean, tabular, and well-defined? Or is it messy, ambiguous, and human-generated?
Process: deterministic vs. non-deterministic. Does the workflow demand the same outcome every time? Or does it require judgement, interpretation, and tolerance for variation?
This gives you four zones:
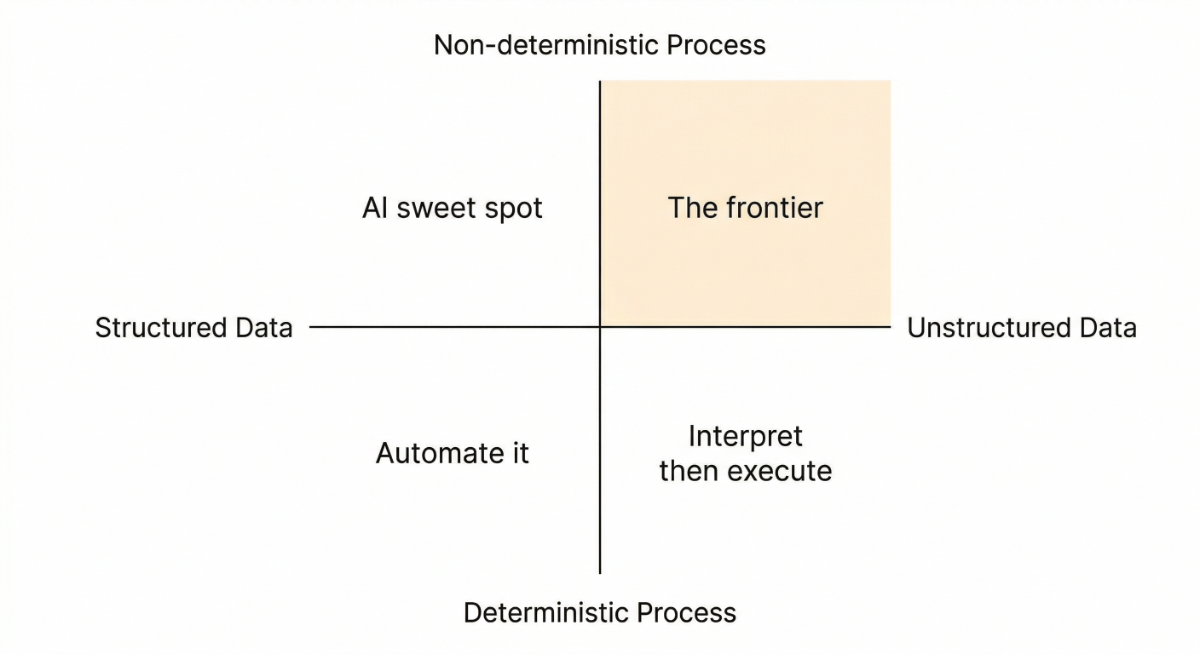
Structured data + deterministic process: just automate it
Data integrations. Asset delivery. Metadata pipelines. Compliance reporting. I've built a lot of these over the years: structured inputs, defined schemas, the correct answer is the same every time. Most enterprise integration work lives here. You're mapping fields, transforming formats, moving data between systems. Traditional automation handles this well. AI introduces risk for no gain. You don't want a probabilistic answer to a field mapping. Forrester found gen AI still orchestrates less than 1% of core business processes. Conventional automation still runs most of this work, and it should.
Structured data + non-deterministic process: AI's sweet spot today
Matching people and experience to proposals. Cleaning and standardising company data. Reporting and analytics. Content recommendation. Risk scoring. Scheduling. The data is solid but the judgement about what to do with it varies. AI can find patterns humans miss, and structured data gives it something reliable to work with. MIT found the biggest ROI in exactly this zone: back-office automation, cutting outsourcing costs, streamlining operations. Vendor-built tools in this space succeed about 67% of the time.
Unstructured data + deterministic process: interpret, then execute
Email triage. Document classification. Compliance screening. Contract review. The input is messy but the downstream workflow is rule-based. AI handles the interpretation; deterministic logic handles what happens next. This is the hybrid pattern: AI reads and classifies, then rules enforce the outcome. It works well when you get the boundary right. Salesforce has been shifting toward exactly this architecture in Agentforce, combining LLM flexibility with rule-based execution.
This is also classic ML territory. Supervised learning was purpose-built for this: take unstructured input, classify it into a structured category, hand off to a deterministic system. Spam detection, sentiment analysis, fraud scoring, image recognition. A fine-tuned BERT model will often do this faster, cheaper, and more reliably than a generative model. Not every AI problem needs an LLM. The hype has pulled organisations toward frontier tools for problems that a classifier would handle better, and that mismatch accounts for a lot of the failure.
Unstructured data + non-deterministic process: the frontier
Coding. Strategy. Creative work. Research. Novel problem-solving. Both the input and the process are open-ended. This is where individual power users report the biggest gains and where enterprise failure rates are highest.
Andrej Karpathy describes the challenge here as the March of Nines . The maths is simple but brutal. Imagine a 10-step agentic workflow where each step succeeds 90% of the time. That sounds decent. But 0.9^10 is 0.35. Your end-to-end success rate is 35%. That's your demo. It looks impressive when it works, and it fails quietly most of the time.
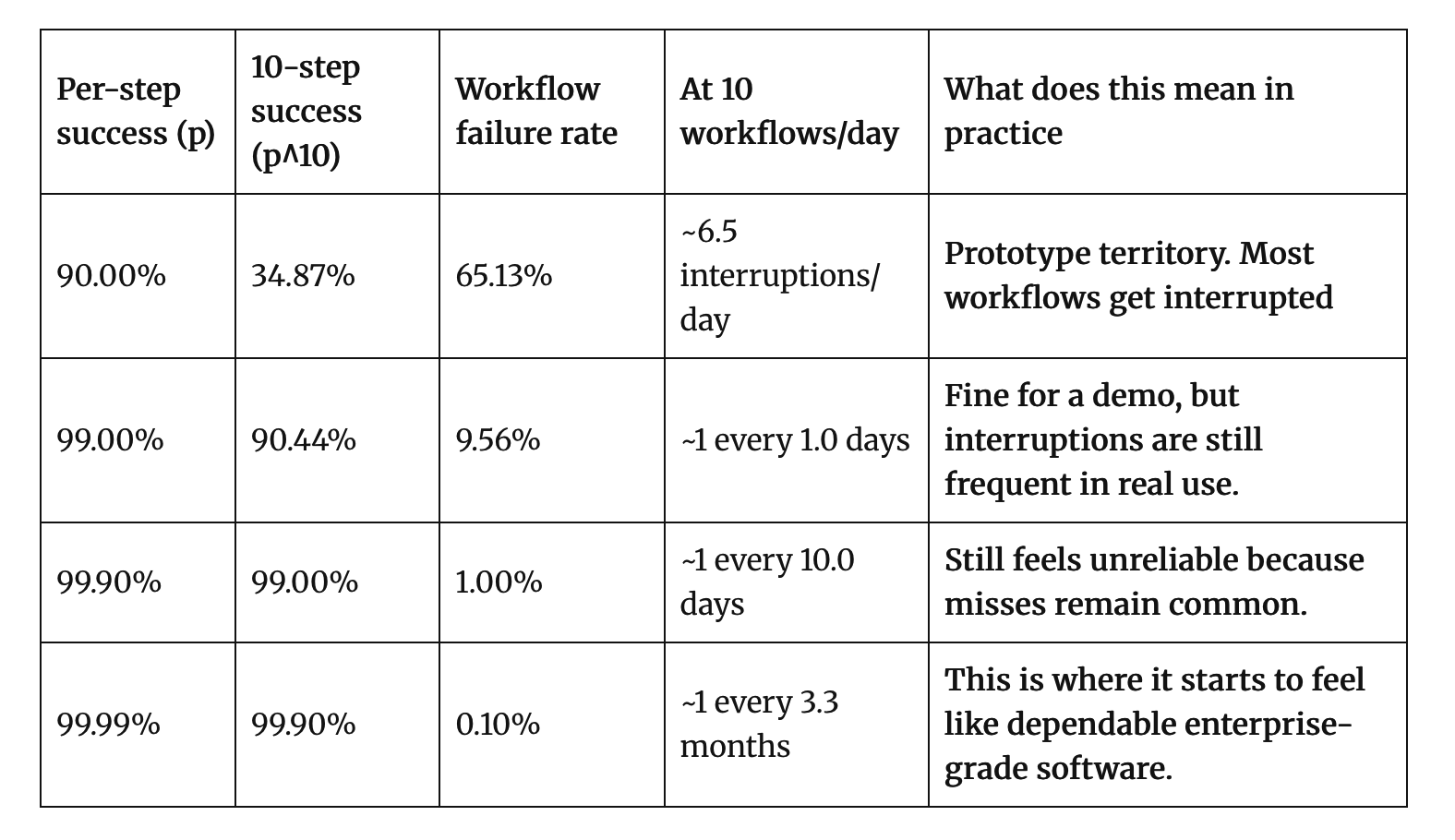
Getting from 90% to 99% per step is one order of magnitude of effort. Getting from 99% to 99.9% is another, roughly equal in difficulty. Each additional nine costs about as much engineering as the last one. At 99% per step, your 10-step workflow lands at 90% end-to-end. At 99.9%, you're at 99%. Production-grade reliability means marching through those nines, and each one is hard-won.
Prompting and agent skills get you to 90%. They're necessary but not sufficient. The remaining nines come from harness engineering: putting AI systems on deterministic rails. Validation at each step. State management so you can resume or retry. Programmatic control over what the model can and can't do. Structured outputs. Assertions on intermediate results. The kind of engineering that isn't exciting but makes the difference between a demo and a system you can trust.
This is why the frontier quadrant has the highest failure rate. The compounding error problem is intrinsic to multi-step AI workflows, and most organisations stop at the demo. They see 90% per step and call it good enough. They don't invest in the harness engineering that turns a promising prototype into something reliable. And when it fails in production, they blame the model.
The frontier is moving
The difference between success and failure in this quadrant isn't the model, it's the engineering around it. And I believe this quadrant is going to keep expanding. Everything that can be codified the way code can be codified is vulnerable to the same kind of disruption. But only if people learn to work with the AI effectively, which most haven't yet.
This is the frontier, and it's moving quickly: better models, better tooling around them, and a growing understanding of how to actually work with them.
The outer loop: getting better at getting better
Most talk about AI in practice focuses on the inner loop: the agent loop. The model receives a prompt, reasons, takes actions, gets feedback, iterates. This is the cycle inside the tool. It's what the AI does.
The outer loop is what you do. It's the feedback practice where you evaluate whether your way of working with AI is actually producing good outcomes, and then adapt your process based on what you learn.
I use AI, it sometimes fails. I examine why, and I adjust my process. The whole approach: how I structure the task. What I verify. Where I intervene. What I delegate. Over time, this compounds. I'm not just using a tool; I'm developing a practice.
The model and the harness improve together. The way I work with AI adapts as the model changes. Some of my process will probably be redundant when models improve further. Maybe. I'm not sure which parts yet, and that uncertainty is exactly why the outer loop matters. Without it, you're either clinging to a process that has become overhead, or you're abandoning discipline still earning its keep. You can't tell which is which unless you're paying attention to outcomes.
As the Codestrap founders put it, companies are measuring lines of code and pull requests (activity metrics) instead of deployment frequency, change failure rate, and mean time to restore (outcome metrics). Without measuring outcomes, there's no signal to feed back into process improvement. The inner loop runs, produces outputs, and nobody asks whether the whole system is actually working.
Rich Sutton's The Bitter Lesson from AI research is relevant here: over 70 years, general methods that leverage computation have consistently beaten elaborate human-designed scaffolding. As models improve, some of the scaffolding you built becomes overhead. But this isn't a simple story. Prompt injection isn't solved. Hallucination isn't solved. Deterministic verification matters where you can get it. Scaffolding that constrains the problem space or validates outputs isn't fighting the model. It's good engineering. The outer loop is about honest, continuous assessment of what's earning its keep. Not ideology about whether scaffolding is good or bad.
Putting it together
Before deploying AI, understand the nature of the problem. Is the data structured or messy? Is the process rule-based or judgement-based?
The research points to several reasons AI initiatives fail: poor data quality, lack of clear success metrics, losing executive sponsorship, treating AI as an IT project rather than a business transformation. These all matter. But one pattern that the quadrant helps explain is tool-problem mismatch: deploying frontier AI into problems that need traditional automation, or throwing chatbots at work that demands carefully engineered hybrid systems. It's not the only cause of failure, but it's one that clearer thinking upfront can prevent.
Match the harness to the zone. Each quadrant needs a different approach. Deterministic problems need deterministic tools. Hybrid problems need a clear boundary between what the AI interprets and what rules enforce. Frontier problems need harness engineering that earns each nine of reliability, and human judgement in the loop as an active participant, not a rubber stamp.
Run the outer loop. Whatever quadrant you're in, build a feedback mechanism that evaluates outcomes, not activity. Are you actually shipping better code, making better decisions, producing better analysis? If you're not measuring this, you don't know whether AI is helping or generating expensive noise.
Hold the tensions. The Bitter Lesson says don't over-engineer scaffolding the model will outgrow. But deterministic verification genuinely matters where you can get it. Prompt injection and hallucination are unsolved. Models are getting better fast, but "better" doesn't mean "trustworthy in all contexts." The outer loop is how you navigate these tensions. Not by picking a side, but by continuously reassessing what's working.
The 95% failure rate isn't a verdict on AI. It's a verdict on how organisations are thinking about it. Or failing to. The people succeeding aren't using better models. They're thinking more clearly about where AI fits, and they're learning and iterating toward getting the best outcomes.
Further reading
- MIT NANDA, GenAI Divide (2025)
- Pertama Partners, AI project failure statistics ( 2026)
- The Register / Codestrap on enterprise AI failures ( 2026)
- Rich Sutton, The Bitter Lesson (2019)
- Andrej Karpathy, The March of Nines ( 2025)
- Ethan Mollick, The Bitter Lesson vs. the Garbage (2025)
- ServicePath, deterministic guardrails for AI ( 2025)
- Zapier, hybrid deterministic + non-deterministic architectures (2026)
- Salesforce, rule-based execution in Agentforce (2025)
- CIO.com, enterprise AI ROI pressure (2026)